Unlocking the Power of Variables in VectorShift: A Comprehensive Guide
Discover the power of variables in Vector Shift's no-code platform. This comprehensive guide explains how to use variables effectively, handle errors, and leverage knowledge bases to enhance your AI-powered applications.
December 14, 2025
Unlock the power of variables in VectorShift's no-code platform and streamline your content creation process. Discover how to seamlessly integrate dynamic data into your pipelines, ensuring your content stays fresh and relevant.
What are Variables and How to Use Them in Vector Shift
Anatomy of a Variable in Vector Shift
Common Errors When Using Variables
Using Variables with the Knowledge Base Node
Passing Variables to the OpenAI Node
What are Variables and How to Use Them in Vector Shift
What are Variables and How to Use Them in Vector Shift
Variables represent pieces of data in the Vector Shift platform. When the pipeline runs, the data will replace the variables.
To use variables in Vector Shift, you can type them in text fields using double curly braces {{ }}. A variable has two parts:
- Node Reference: This references the name of the node, such as
input0. - Output Field: This references the output field of the node, such as
text.
You can change the node name by editing the text within the double curly braces. To remove a variable, click the delete icon next to it.
Common sources of variable errors include:
- Using a node that is not connected to the pipeline
- Using an invalid variable name (e.g.,
input0.textwhen there is noinput0node)
You can pass data between nodes using variables. For example, you can pass the output of the Knowledge Base node's chunks field to the input of the OpenAI node's context field. The user's question can be passed to the question field, and the response from the OpenAI node can be sent to the output node.
Anatomy of a Variable in Vector Shift
Anatomy of a Variable in Vector Shift
Variables in Vector Shift represent pieces of data that are used to power the various nodes in your pipeline. When the pipeline runs, the actual data will replace the variables, allowing the nodes to process the information.
To use variables in Vector Shift, you can type them directly into the text fields by enclosing the variable in double curly braces {{ }}. A variable has two main parts:
-
Node Reference: This specifies the name of the node that the variable is referencing. For example, if you have an "Input" node, the node reference would be
input0. -
Output Field: This specifies the output field of the referenced node that you want to use. For example, the "Input" node may have an output field called "text" that represents the user's input.
To construct a variable, you would use the syntax {{node_reference.output_field}}. For example, {{input0.text}} would reference the "text" output field of the "input0" node.
You can also rename the node reference by editing the text within the double curly braces. This can be useful for making your variables more descriptive. Additionally, you can remove a variable by clicking the "Delete" button next to it.
Common sources of variable errors include:
- Using a node that is not connected to the pipeline
- Referencing an invalid node or output field
- Misspelling the node reference or output field name
By understanding the anatomy of variables in Vector Shift, you can effectively leverage them to power your no-code pipelines and create dynamic, data-driven applications.
Common Errors When Using Variables
Common Errors When Using Variables
When using variables in the Vector Shift no-code platform, there are a few common errors that you may encounter:
-
Referencing Unconnected Nodes: If you try to use a variable that references a node that is not connected in your pipeline, you will get an error message indicating that the node is not connected. To fix this, you need to connect the node or update the variable to reference a connected node.
-
Using Invalid Variable Names: Variables in Vector Shift have a specific format, consisting of the node name and the output field, separated by a period. If you try to use a variable that doesn't match this format, you will get an error. Make sure to double-check the variable name and format.
-
Referencing Non-existent Nodes: If you try to use a variable that references a node that doesn't exist in your pipeline, you will get an error. Ensure that the node name in the variable is correct and matches a node in your pipeline.
-
Referencing Incorrect Output Fields: Each node in your pipeline has specific output fields that can be referenced in variables. If you try to use an output field that doesn't exist for a particular node, you will get an error. Review the available output fields for each node and use the correct one in your variables.
By being aware of these common errors and double-checking your variable usage, you can avoid issues and ensure that your Vector Shift pipelines run smoothly.
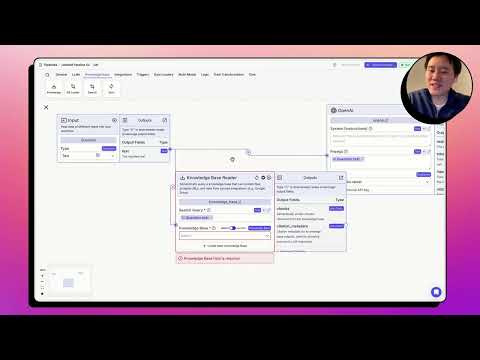
Using Variables with the Knowledge Base Node
Using Variables with the Knowledge Base Node
The Knowledge Base node in the Vector Shift no-code platform allows you to retrieve semantically similar information from a knowledge base and pass it as context to the Large Language Model. To use variables with the Knowledge Base node, follow these steps:
- Connect the Input node to the Knowledge Base node.
- In the Knowledge Base node, the default name is
knowledgebase_0, and it has two output fields:chunks(semantically similar information) andcitation_metadata(source information). - To pass the
chunksoutput to the Large Language Model, use the variable{{knowledgebase_0.chunks}}. - You can also pass the user's question as a variable by using
{{question.text}}. - Connect the Large Language Model node to an Output node to display the response.
When the pipeline runs, the user's input will replace the {{question.text}} variable, and the semantically similar information from the Knowledge Base will replace the {{knowledgebase_0.chunks}} variable. This allows you to dynamically pass data between nodes in your pipeline.
Passing Variables to the OpenAI Node
Passing Variables to the OpenAI Node
To pass variables to the OpenAI node, you can use the double curly braces {{ }} syntax to reference the output fields of other nodes in your pipeline. Here's how it works:
- Identify the node and output field you want to pass as a variable. For example, the
knowledge_base_0node has an output field calledchunksthat contains the semantically similar information retrieved from the knowledge base. - In the prompt input field of the OpenAI node, use the double curly braces to reference the node and output field. For example,
{{ knowledge_base_0.chunks }}will pass the contents of thechunksoutput field to the OpenAI node. - You can also define your own variable names by using the double curly braces. For example,
{{ question }}will allow you to reference the user's question in the prompt. - Make sure that the nodes you are referencing are connected to the OpenAI node, and that the output fields exist. If you reference a non-existent node or output field, you will see an error.
By using variables, you can dynamically pass data from one node to another, allowing your pipeline to adapt to different inputs and contexts.
FAQ
FAQ

